.webp)
AI in biotech doesn’t fail because models are weak. It fails because lab data is messy. No matter how advanced your models are, if your data inputs are unstable, unstructured, or riddled with gaps and inconsistencies, your AI initiative will stall before it starts. This is the silent killer of automation in life sciences—one that Scispot’s LabOS is solving by rearchitecting the digital foundation of modern labs.
Most life science labs still run on a patchwork of disconnected systems. Instruments speak in strange dialects. Files are dumped into shared drives, where version control becomes a guessing game. Researchers often copy and paste data between tools, while context lives in people’s heads or is buried in inconsistent spreadsheets. Over time, this causes more than just model drift. There’s process drift, naming drift, and even meaning drift—where the same term might mean something different to different teams. This chaos breaks AI, which relies on clean, stable data structures. AI needs lineage, context, and order. Without them, the best-trained models are left guessing.

Think of a lab without a digital core like a kitchen with premium ingredients but no pantry map. You have what you need to make a great meal, but you spend so much time searching for ingredients and tools that the process becomes inefficient, error-prone, and slow. You end up cooking slowly and guessing your way through recipes. Scispot’s LabOS brings structure to this chaos by making labs truly AI-ready—not by dumping everything into a “data lake” but by providing the five foundations that make structured data usable from day one.
The first of these is typed capture. Every field in Scispot’s Labsheets is defined with a specific type, units, and validation rules. This ensures that data has semantic meaning and can be trusted downstream. The second pillar is the linkage of entities. Samples, runs, plates, lots, instruments, and users are all connected through IDs in an entity graph. This enables seamless traceability, making it easy to understand how every record connects to real-world processes. Next comes lineage. Scispot preserves the story behind every piece of data—who created it, when, and what it was derived from. This turns audit trails into simple queries, not weeks-long fire drills.
Fourth, Scispot enables event hooks. These are automated triggers that respond to specific data events. For example, when a sequencing run finishes, it can automatically trigger a quality control workflow, pass clean results to an analysis pipeline, and flag edge cases for human review. The final key component is clean integration via APIs. Scispot is designed for modern labs that want to connect ELNs, MLOps platforms, and BI tools without scraping or hacks. Integration is programmatic, governed, and efficient.
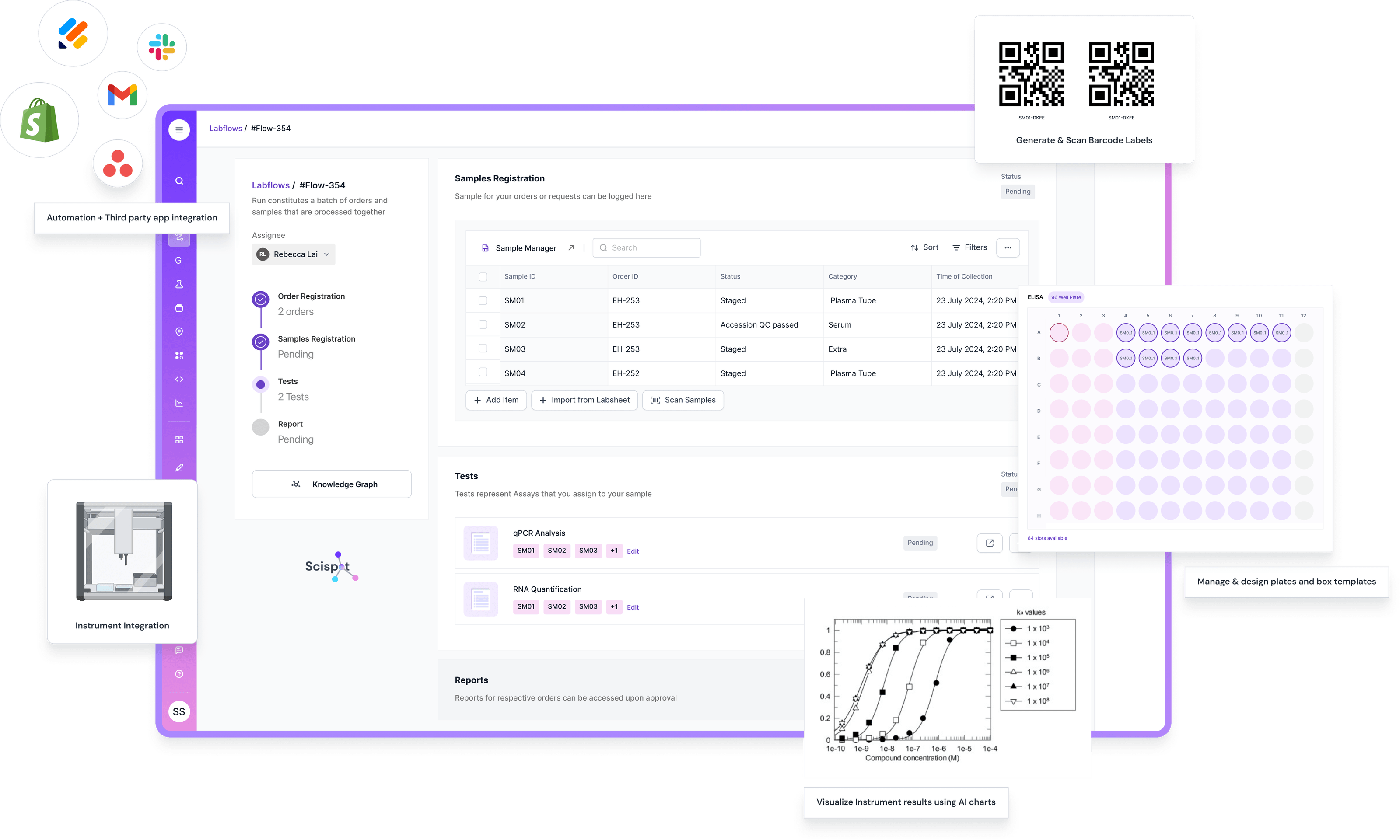
Scispot’s approach can be visualized as a flow: Instruments and lab apps push data through SDKs and APIs. That data is parsed into typed Labsheets that enforce validation rules and defaults. These Labsheets feed into an entity and lineage graph, linking all relevant IDs—samples, runs, lots, instruments, operators—into a structured network. On top of this foundation sits an event bus that reacts in real time, sending data through automated rules. The end result is clean outputs into analytics dashboards, AI tools, LIS alternatives, or exports for partners and stakeholders.
This system works in practice because Scispot has built the right primitives. Labsheets enforce field types, required values, and valid ranges, which prevents messy data from ever entering the system. Labspace provides teams with a project-oriented workspace, including roles, access controls, and review checkpoints, ensuring structured collaboration. The entity graph eliminates orphaned records and preserves relationships between experiments, people, and instruments. Scispot’s APIs and SDKs allow teams to connect everything from Jupyter notebooks to Power BI dashboards with minimal overhead. Meanwhile, immutable audit logs capture every change, supporting compliance with regulations like 21 CFR Part 11.
To understand what this looks like in the real world, consider a genomics team that pulled data from 11 instruments into Scispot Labsheets. They defined rules for sample IDs, set thresholds for read depth, and flagged contamination risks. Clean runs were routed automatically into variant-calling pipelines. Edge cases were flagged for human review. The result was a massive reduction in quality control cycle time—from two days to just two hours. This wasn’t a result of heroic effort or new models. It was simply the outcome of replacing scattered spreadsheets with typed, structured data and automation.
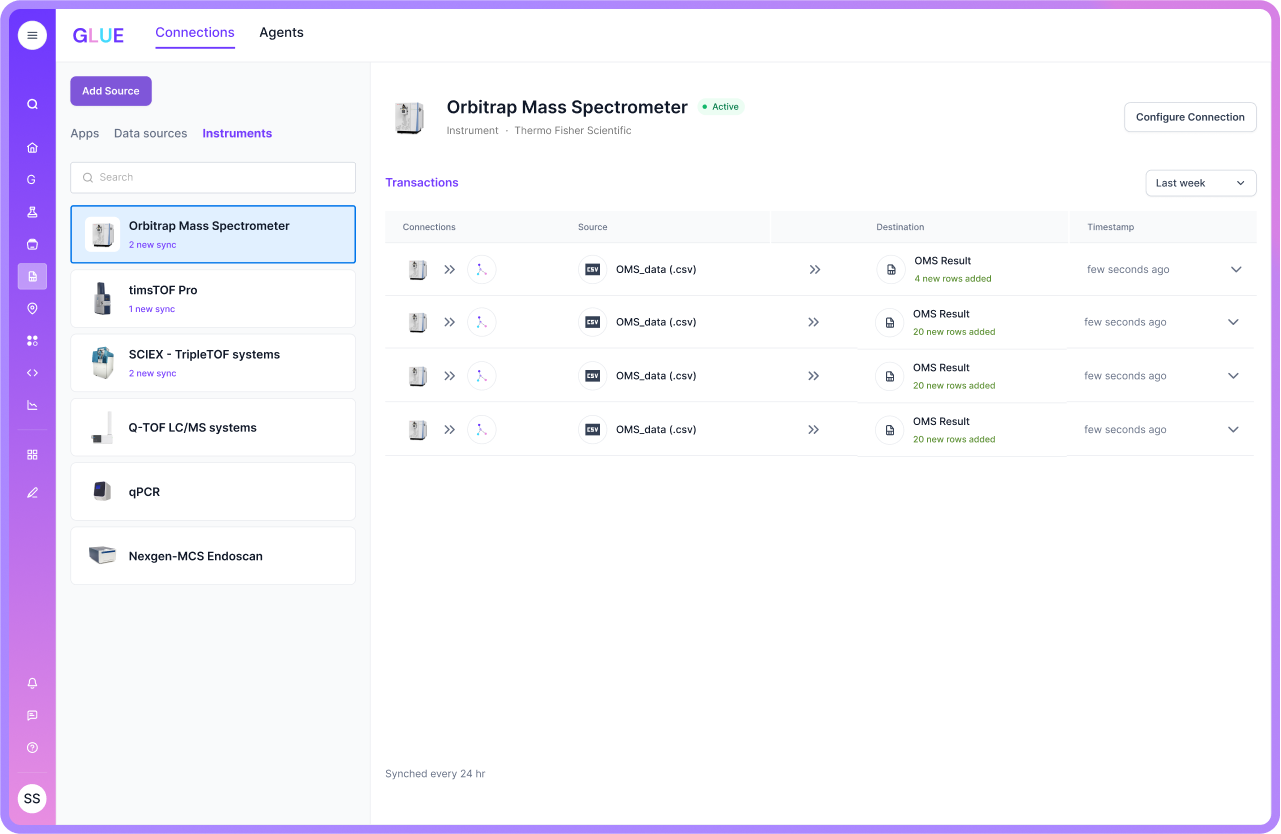
Scispot doesn’t demand a massive migration to get started. In fact, the most effective way to implement LabOS is to begin small and scale fast. Choose a workflow where the pain is real and recurring—like sample intake, sequencing analysis, or batch QC. Model your key entities and assign IDs to each—samples, assays, instruments, plates, and users. Design Labsheets that enforce structure with required fields, standard units, and valid ranges. Connect a single instrument or data source using an API or file watch. Validate data on ingest, not in post-hoc reports. Wire event hooks so that new data automatically triggers quality checks, analytics, or model runs. Expose data to downstream systems via APIs and measure key metrics such as error rate, data freshness, and lineage completeness. Once the initial flow is stable, you can bring in the next assay, instrument, or team.
As you scale, it’s essential to track the right metrics. These include data error rate—how many rows are malformed per thousand—data freshness —the lag between an experiment finishing and its data becoming usable —and lineage coverage, the percentage of records with complete provenance. Reproducibility is another key measure, indicating how many analyses can be repeated solely from stored lineage. Finally, model input completeness tracks whether required fields are present, typed, and validated before feeding your AI.

There are also pitfalls to avoid. One of the most common is folder-based thinking—relying on filenames and folders as your primary data structure will lead back to drift. Free-text sprawl is another risk: Notes belong in your ELN, but core data must be structured. Avoid migrating everything at once; instead, wrap your current processes in typed capture and replace them gradually. Don’t allow shadow schemas to evolve in your BI tools or MLOps platforms; these will become silent sources of drift if they differ from your core data spine.
Like any platform change, implementing LabOS has risks—but these can be managed. Change fatigue is real, so keep early wins small and visible. Avoid rigid templates at the beginning; start permissive and introduce stricter validation rules over time. Prevent governance bloat by treating policy as code and reviewing it quarterly. Most importantly, avoid model overreach. Use human-in-the-loop review for workflows where the stakes are high, while automating the rest.
The benefits of using Scispot’s LabOS are clear. Labs move faster, with fewer rework cycles. Data becomes trustworthy and traceable. AI models become effective sooner, needing less post-processing and guesswork. Regulatory audits, which once took weeks, now take hours. Of course, there is some upfront modeling effort involved, and teams will need to adapt culturally to the idea of typed data and structured workflows. But with clean APIs, event triggers, and lineage-first design, the payoff is well worth the discipline.
At its core, Scispot is redefining what it means to be “AI-ready” in biotech. It’s not about having more data—it’s about having data that is structured, linked, and live. It’s about having systems that capture meaning and context from the start, so your models don’t have to guess later. If your lab has great ingredients but slow processes, maybe it’s time to map the pantry. The future of biotech is not just digital. It’s structured, event-driven, and AI-native. With Scispot’s LabOS, that future starts today.