Modern life science labs are under pressure to be both innovative and efficient, yet many labs unknowingly carry a heavy burden in the form of fragmented data systems. Over time, a typical lab might adopt an Electronic Lab Notebook (ELN) for experiment records, a Laboratory Information Management System (LIMS) for samples, separate inventory and procurement trackers, instrument-specific software, and various analysis tools. Each system serves a purpose, but when they operate in isolation, they create data silos that impede information flow. The result is an integration nightmare – lab staff spend countless hours manually transferring data between systems, reconciling discrepancies, and maintaining brittle custom links. In an environment that demands agility, such disconnected systems "create data silos, increase manual workloads, and hinder decision-making."
This post takes an analytical look at the hidden costs and complexity of these fragmented lab systems, and why a unified approach is the antidote.
Fragmented Lab Systems: How Silos Form in Modern Labs
Life science labs rarely start out intending to silo their data. Fragmentation often happens gradually as labs implement new software to meet immediate needs without fully considering integration. For example, a research team might add a new inventory app or a specialized analysis tool on the fly. However, when these tools aren't integrated, data remains scattered. As one industry analysis notes, businesses commonly introduce new platforms to solve problems "without considering how these tools will integrate with existing systems. The result? Fragmented data, inconsistent reporting, and missed opportunities."
Lab managers end up juggling multiple logins and exports: experimental results in an ELN, sample metadata in a LIMS, reagent orders in an ERP, instrument readings in CSV files, and so on. Such fragmentation in labs directly leads to data silos and inefficiencies. A recent Scispot review of legacy lab platforms observed that labs often wind up with "fragmented systems – one for instrument data, one for inventory, another for analysis – that don't talk to each other," forcing teams into "manual data transfer or tedious CSV imports" and inevitably "introducing errors and wasting time."
In other words, each additional system becomes another island of data that must be painstakingly bridged. Lab IT teams face an uphill battle trying to stitch these systems together, often with ad-hoc scripts or manual workflows. The more systems added, the more the integration overhead grows – and it doesn't grow linearly.

Point-to-Point "Spaghetti": Integration Complexity Grows Exponentially
To understand the true cost of unintegrated lab systems, consider the integration architecture. In many labs, every software tool or database is connected (if at all) in a point-to-point fashion – meaning each system must directly interface with each other system that needs its data. This approach quickly turns into a tangled web of connections. When visualized, it looks like a spaghetti bowl of lines between systems – exactly what the "un-integrated" architecture diagram illustrates.
In that diagram, each lab system has multiple direct connections to others, representing custom integrations or data exchange pipelines. As the red annotation on the diagram suggests, the complexity of managing such a network "scales quadratically as a function of n data stores to synchronize." Every new application isn't just one additional connection – it potentially needs to link with all the existing applications, multiplying the number of interfaces.
Mathematically, the worst-case number of point-to-point integrations for n systems is n(n–1)/2. This reality was famously described by Fred Brooks in The Mythical Man-Month regarding communication paths: "the number of potential connections… grows quadratically, not linearly."
Just as five people have 10 possible pairwise communication channels, while 50 people have 1,225, a lab with 10 disparate systems could theoretically require 45 separate integrations to fully synchronize all data. Even if not every pair of systems in a lab needs a direct link, the integration workload explodes with each added silo.
The unintegrated architecture diagram underscores this: multiple LIMS/ELN/instrument databases all cross-connected, leading to redundant links and a high maintenance burden. Industry experts often call this the "spaghetti integration" problem – a mess of point-to-point connectors that becomes increasingly fragile. As one integration platform described, when poorly managed "it can lead to 'spaghetti integration,' in which software applications are messily or redundantly synced."
This complexity isn't just an IT headache; it translates to real costs in time and money. Integration complexity grows exponentially in a point-to-point model. To put it simply, if one system is manageable and two systems might need one link, by the time you have a dozen systems you're dealing with dozens of links and interfaces. Each interface might require custom code, maintenance, updates when either system changes, and troubleshooting when data doesn't align. Lab IT staff can end up spending more time maintaining integrations than supporting science. Meanwhile, scientists face delays waiting for data to sync or appear in the right place, or resort to manually patching the gaps. The integration overhead in this model can easily overshadow the benefits of adding a new tool.
Unified Architecture: A Hub-and-Spoke Model Scales Linearly
There is a better way to integrate lab systems: the hub-and-spoke (unified) architecture. In this model, all systems connect through a single unified data layer or platform – a central "hub" – rather than directly to each other. The "integrated" architecture diagram illustrates this clearly. Instead of many-to-many connections, every lab application (instruments, ELN, LIMS, inventory, etc.) has one connection – to the central hub. This drastically reduces the total number of interfaces. The complexity scales linearly with the number of systems: adding a new system simply means plugging it into the hub, not rewriting integrations with every other tool.
In a hub-and-spoke design, integration is inherently simpler. Each system speaks to the central platform using a standard API or connector, and the platform mediates all data exchange. The difference in complexity between the two models is profound: 10 systems would require 10 connections (to the hub) instead of up to 45 bespoke connections in a peer-to-peer web. As a result, integration effort and cost grow at a much lower rate as the lab adds more instruments or software.
Industry data backs this up – one report notes that as organizations grow, "integrated systems help scale operations without adding complexity. For example, adding new applications to a centralized platform is simpler than creating separate custom integrations."
In other words, a unified architecture contains complexity instead of letting it explode. By simplifying the integration topology, the unified approach also improves reliability and data consistency. There are fewer moving parts where things can break or fall out-of-sync. The centralized data layer acts as the single source of truth for the lab, ensuring every tool draws from and contributes to the same dataset.
This hub model is the principle behind modern integration platforms and enterprise service buses in IT, and it's now becoming a best practice for data-heavy labs as well. Laboratories that adopt a unified Lab Operations System (a "Lab OS") effectively transform their infrastructure from a brittle spaghetti of point-to-point links into a robust wheel where all spokes lead to one strong hub.

The Cost Curves: Unintegrated vs. Integrated Growth
What do these different architectures mean in terms of actual IT overhead and cost? The contrast is striking when modeled. Consider an example scenario of scaling from 1 system to 10 systems. In a unified architecture (hub-and-spoke), the IT integration overhead might roughly double – e.g. 2× the baseline – because each new system adds an incremental load that grows in proportion. In a fragmented, point-to-point architecture, however, the overhead grows almost exponentially. Modeling integration and maintenance effort for 10 siloed systems shows an increase of about 5.4× the IT overhead compared to the single-system baseline. In other words, going from 1 system to 10 systems could demand over five times the integration effort and cost in a disjointed setup, versus only twice the effort in a unified environment.
Figure: Integration Cost Trajectories. A modeled cost comparison shows how IT overhead scales with number of lab data silos in two architectures. The unintegrated (point-to-point) approach (yellow line) leads to a steep curve – about 5.4× increase in overhead when growing from 1 to 10 systems – reflecting the quadratic explosion of integration complexity. The integrated (hub-and-spoke) approach (orange line) grows much more slowly – roughly 2× overhead at 10 systems – as new systems only require one connection each. The gap between the curves (red dashed line) represents the "ROI" or savings achieved by the unified model: at 10 silos, the lab would be saving the equivalent of ~3.4× its baseline IT budget in avoided overhead.
In practice, this means a unified data platform frees up significant IT resources and budget that would otherwise be consumed by wrangling dozens of custom integrations. This cost model is not just theoretical. It encapsulates the everyday reality that lab IT teams observe: beyond a certain point, each new isolated system adds disproportionate burden. Integrations don't just add up – they start to compound in complexity. Without a unified strategy, a lab with 10+ different software tools might need to dedicate multiple full-time IT personnel just to keep data flowing between them (writing scripts, fixing API mismatches, updating file formats with each software upgrade, etc.).
The increasing overhead can also manifest as slower turnaround times for changes (since any process update might require coordinating several systems) and higher risk of downtime or errors (since there are more failure points). By contrast, labs that invested early in integration – or better, in a unified Lab OS – find that adding a new instrument or app is far less painful. It's a one-time setup to connect to the hub, with the heavy lifting of data mapping done by the central platform. This yields a network effect in reverse: instead of each addition creating exponential work, it benefits from the existing unified data model.
The line graph above encapsulates this difference in trajectory. While exact numbers will vary by lab, the order-of-magnitude difference is clear. Over a few years, the cost divergence can translate into hundreds of thousands of dollars in saved labor and integration expenses, not to mention faster scientific output. For instance, one analysis found that 30% of the time being spent on paperwork for 20 employees… equals $312,000+ every year in labor cost – a massive hidden cost that an integrated system could shrink by automating data capture and exchange. The ROI of integration is both the avoidance of escalating IT costs and the unlocking of scientific productivity that would otherwise be trapped in admin overhead.
The Hidden Costs of Data Silos and Fragmentation
Beyond the direct IT integration effort, fragmented lab systems incur a host of hidden costs and risks. These often go unnoticed by management until they become acute problems. Here are the key areas where data silos quietly drain resources and introduce complexity:
Manual Data Entry and Transfer: When systems aren't connected, staff must re-enter or copy-paste data from one system to another. This is tedious and error-prone. Scientists might transcribe instrument readings into an ELN, or export sample info from a LIMS into a spreadsheet. Such manual workflows consume valuable researcher time and are highly susceptible to typos and transcription errors. Studies have shown that manual data handling can eat up significant portions of lab work hours, translating into large labor costs (as seen in the €312k+/year example above). Moreover, every manual step is a point of possible failure. If one person forgets to update the inventory after using a reagent, the inventory system diverges from reality. These small errors can snowball into experiment delays or regulatory issues down the line.
Repeated Integration Efforts: In a siloed environment, integrations are often one-off projects. Need to pull QC data into a reporting tool? You might script a custom CSV export from the QC system. Later, need the ELN to talk to inventory? That's another separate integration project. Teams end up reinventing the wheel for each pair of systems. This piecemeal approach is not only inefficient; it also means maintaining a patchwork of scripts and connectors. Whenever a software vendor updates an API or a database schema changes, multiple integration points may break. IT teams then scramble to patch each one. The cumulative burden of these "point solutions" is significant. As Panorama Consulting reports, "maintaining disparate systems with unique support requirements strains IT budgets," often requiring specialized staff for each system. In essence, fragmentation forces labs to devote resources to integration maintenance instead of innovation.
Higher Error Rates and Inconsistencies: Data silos mean that information is duplicated across systems (e.g. sample IDs in both ELN and LIMS) or exists in one system but not automatically reflected in another. This leads to version control problems and discrepancies. It's common to find that two databases in a lab have slightly different values for what should be the same metric, simply because they were updated at different times. Identifying and reconciling these inconsistencies is a hidden time sink. Furthermore, when analysts try to combine data from silos, they might inadvertently use outdated or mismatched data, skewing results. A disconnected lab environment "increases the risk of human error" and even requires extra effort to "rectify inconsistencies, which incurs further expenses." The cost of errors can be monumental in science – from having to repeat experiments to regulatory non-compliance if audit data is wrong.
Compliance and Quality Burdens: Labs in regulated industries (pharmaceuticals, diagnostics, etc.) face stringent compliance requirements. Demonstrating data integrity and traceability (think FDA 21 CFR Part 11 or GLP/GMP guidelines) is much harder when data is spread across siloed systems. Poor integration can result in "incomplete audit trails, making it difficult to demonstrate compliance." During an audit or quality check, teams might have to pull records from five different systems and manually stitch together a timeline of an experiment – a stressful and error-prone process. Each silo might have its own login controls and logs, but no unified view of who did what, when. This fragmentation raises the risk of compliance gaps: e.g., a sample's chain of custody might be broken between a LIMS and an instrument file. The hidden cost here is twofold: operational overhead (extra work to prepare compliance reports, validate across systems, etc.) and risk (potential fines or project delays if compliance issues are found). Many labs end up over-compensating with SOPs and manual cross-checks to manage this risk, which is essentially a cost of not having integrated systems.
Inefficient Resource Utilization: Data silos also lead to inefficient use of resources and duplicated efforts. For instance, two different teams might unknowingly be maintaining parallel datasets of the same information (say, separate inventory lists in two departments) because no system connects them. Fragmentation often means redundant workflows, where "separate teams verify the same data, leading to duplicated tasks and unnecessary allocation of resources." It can also mean paying for overlapping functionalities in different software subscriptions (one group pays for a standalone analysis tool while another's LIMS has a similar module unused). From an IT perspective, multiple siloed systems often mean multiple infrastructures (servers, databases) to support, each with its own licensing and maintenance fees. All of this adds up. Lab executives might not see these costs on a single line item in the budget labeled "silos," but they manifest as a larger total cost of ownership for IT and lower overall lab efficiency.
In short, fragmented lab systems impose a tax on every activity: scientists spend more time as data wranglers, IT spends more time as system integrators, and leadership has less reliable information to base decisions on. These hidden costs erode both the bottom line and the lab's ability to scale. The good news is that eliminating silos yields the opposite effect – compounding benefits across operations, cost, quality, and speed. To achieve that, labs are increasingly looking to unify their digital infrastructure.
Scispot's Unified Lab Operating System: One Data Layer for the Lab
.png)
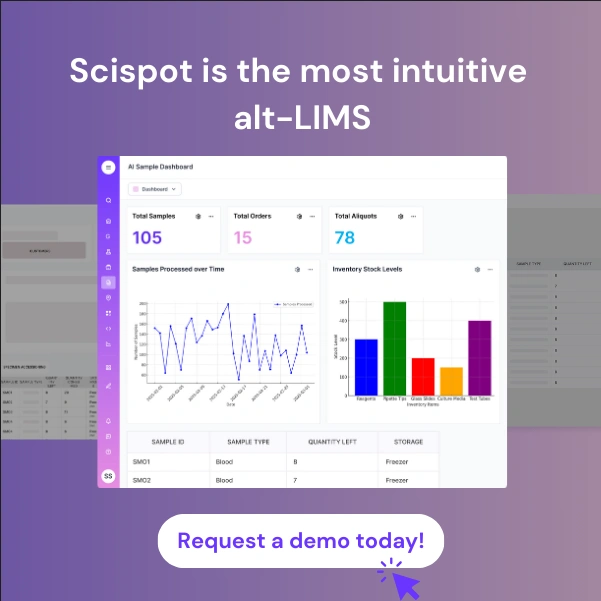
So what's the solution to the quagmire of silos? The solution is integration by design – adopting a unified platform that serves as the lab's central data backbone. This is exactly the approach behind Scispot's Lab Operating System (LabOS). Scispot positions its platform not as just another ELN or LIMS, but as a unified data and workflow layer for all lab operations.
In practice, Scispot LabOS combines the functions of an ELN, LIMS, inventory management, instrument integration, and more on a cloud-based, API-first architecture. Instead of having separate apps for each need, labs using Scispot have a single connected system where all those needs are modules on one data foundation. In the "integrated" architecture diagram, imagine the central hub as Scispot LabOS. Every instrument, app, and process in the lab connects to it. This means an HPLC machine, for example, can stream its results straight into Scispot's data lake; scientists can design and execute protocols within the same platform; inventory usage can be logged automatically as experiments progress; and analytical dashboards or AI tools can pull from the same unified dataset.
Scispot's API-centric design ensures that if a new tool or instrument comes along, it can be plugged into the platform with minimal hassle – the hub's open interfaces are ready to accept and send data as needed. Labs are not stuck waiting for a vendor to build a specific integration; they have full control to integrate or extract data as needed, which "ensures that your data is never trapped" and eliminates the traditional vendor lock-in.
Crucially, Scispot LabOS eliminates the data silos by unifying all lab information in one place. As Scispot describes, all data – whether structured records or raw instrument files – gets ingested into a scientific data lake, "so that all lab data gets unified (no more scattered silos of spreadsheets and servers), and is immediately available for use." This unified data layer acts as the single source of truth for the lab.
For lab managers and scientists, this translates to huge time savings: instead of searching across five systems for a piece of data or manually merging spreadsheets, they can query one system and get the complete answer. One integrated platform means one audit trail captures every action (who uploaded that instrument data, who modified that sample record, etc.), simplifying compliance. It also means experiments, inventory, and results all link together – you can trace a result back to the exact batch of reagent and instrument run that produced it, without leaving the system.
From an integration complexity standpoint, Scispot LabOS embodies the hub-and-spoke efficiency. The lab's apps and instruments become the "spokes" connected to Scispot (the hub). For example, using Scispot's GLUE Toolkit, labs can set up one-click integrations with common lab instruments or external apps. Instead of custom-coding each interface, Scispot provides out-of-the-box connectors and an agent system to talk to machines on the bench. This vastly reduces the effort to bring instrument data online.
Workflow automation is another strength: Scispot can trigger processes between components (for instance, automatically update inventory levels when an experiment is marked complete, or notify team members in Slack when a result is ready). By orchestrating workflows through a single platform, labs avoid the pitfalls of data getting "stuck" in one app waiting for someone to move it to the next. Scispot essentially acts as the lab's central nervous system – integrating instruments, apps, and data flows in real time.
Benefits: Lower IT Overhead, Simplified Compliance, and Scaling with Ease
A unified Lab Operating System like Scispot yields tangible benefits that directly address the hidden costs we discussed. For lab IT teams, one immediate win is dramatically lower integration overhead and cost. There are fewer systems to individually babysit and far fewer custom links to maintain. Many manual workflows can be fully automated, freeing IT and scientists from menial data duties. The difference shows up in the bottom line: labs can support more instruments and software without needing to linearly increase IT headcount or budget. In fact, by avoiding the exponential integration burden of point-to-point systems, labs can often expand their R&D capabilities with existing resources. The earlier cost model showed a ~3.4× budget savings by 10 systems – in practice, that could mean a small bioinformatics team is able to manage integrations for 50 instruments with a unified platform, whereas previously even 10 instruments across siloed systems overwhelmed them.
Another crucial benefit is simplified compliance and quality management. With all data and workflows unified in one system, generating a complete audit trail or compliance report becomes straightforward. Scispot, for example, has built-in compliance features like electronic signatures, version control, and role-based access – these apply uniformly across all modules (ELN, LIMS, etc.), ensuring nothing falls through the cracks. When regulators or QA auditors ask for evidence, labs don't have to pull data from disparate sources and reconcile them; they can rely on the integrated system's records. A unified platform also reduces error rates by keeping everything consistent – the moment a value is updated, all parts of the system see the same update (no divergent databases to reconcile). This integrity of data is invaluable for maintaining GxP standards. Essentially, integration moves compliance from a painful afterthought to a largely automated aspect of routine lab operations. As one source put it, in heavily regulated environments, "precise and unified data management" is key, and unified systems make it far easier to demonstrate compliance than fragmented ones.
Operational efficiency and scalability are also greatly enhanced. Lab staff can focus on science rather than clerical tasks. When all systems interconnect seamlessly, a lot of previously manual steps vanish: inventories update themselves, analyses run on schedule with fresh data, reports compile with a click. This efficiency not only saves time but also improves morale – scientists and analysts can trust that the data they need is at their fingertips in one place. From a management perspective, having integrated data provides real-time visibility into lab operations. Managers and CXOs can get comprehensive dashboards (experiments progress, resource usage, pipeline bottlenecks) without waiting weeks for someone to assemble the data. In modern labs, that agility can be a competitive advantage – the lab can iterate faster and adjust decisions with confidence.
Finally, a unified LabOS sets the stage for future growth. With a solid integration backbone, scaling up doesn't mean exponentially more complexity. Adding a new lab location, onboarding a new team, or implementing a cutting-edge instrument can be done without reinventing the data architecture. This is particularly important for biotech companies that may need to scale from a small R&D lab into a full commercial operation. Scispot's cloud-based architecture, for instance, can elastically scale storage and computing as data grows, so performance remains steady as you go from managing hundreds of samples to millions. And because the platform is modular, labs can enable new functionalities (say, a quality management module or an AI analysis tool) when needed, without deploying an entirely separate system. This means fewer resources needed for scale – the same unified platform supports you at 5 scientists or 500 scientists, at one site or globally. Labs don't face the dreaded "rip-and-replace" of core systems as they expand, avoiding costly migrations that fragmented setups often require.
In summary, integration is not just IT hygiene; it's a strategic enabler. By unifying lab systems, an organization can reduce direct IT costs, minimize compliance risk, and empower their teams to be more productive and innovative. Whether it's eliminating the waste of manual data handling (with its six-figure price tag in labor) or speeding up decision cycles by having all data in one dashboard, the benefits are both quantifiable and qualitative.
Conclusion: Integration as a Cost-Control and Growth Strategy
For life science lab managers, IT leads, and executives, the writing on the wall is clear: the era of isolated point solutions is over. The hidden cost of fragmented lab systems – in dollars, hours, and headaches – is simply too high to ignore. In today's data-driven, fast-moving R&D environment, integration is not a luxury – it is mission-critical. A fragmented lab might function day-to-day, but as it grows, cracks will widen in the form of ballooning IT efforts, slower research cycles, and mounting compliance risk.
On the flip side, labs that invest in unified data architectures gain a compound advantage. They run leaner (by avoiding duplicate systems and work), they innovate faster (with all data readily available to fuel insight), and they scale smarter (without the complexity curve choking progress). The strategic message is this: treat integration as a first-class priority, not just an IT afterthought. It's as much about controlling costs as it is about enabling growth. Every manual process eliminated, every silo bridged, is resources freed to focus on science and product development.
Modern Lab Operating Systems like Scispot exemplify how integration can be baked into the lab's DNA – providing a single platform that grows with your needs, keeps you compliant with minimal fuss, and turns data into a true asset rather than a management burden. By breaking down data silos and unifying workflows, labs position themselves to achieve more with fewer resources.
In the end, integration isn't just about connecting systems – it's about connecting people, processes, and goals. It ensures that your brilliant scientists, diligent technicians, and savvy analysts are all working from the same playbook, with the same information. For a CXO, that means clearer insights and better strategic decisions. For an IT lead, it means a stable, secure infrastructure that doesn't spiral out of control as you grow. And for a lab manager, it means operations that run like clockwork rather than a Rube Goldberg machine of workarounds.
The hidden costs and complexity of fragmented lab systems are very real, but they don't have to be a fact of life. With a unified lab platform strategy, integration becomes your strength – a source of efficiency and agility. It's not just IT hygiene; it's smart business. By unifying your lab's data layer today, you are effectively buying an insurance policy for tomorrow's growth, ensuring that as your science scales, your costs don't scale out of proportion. In the competitive landscape of modern life science, those who master integration will have a decisive edge – achieving breakthroughs unhindered by bottlenecks, and scaling discoveries into solutions with the wind at their backs.


.webp)
.webp)